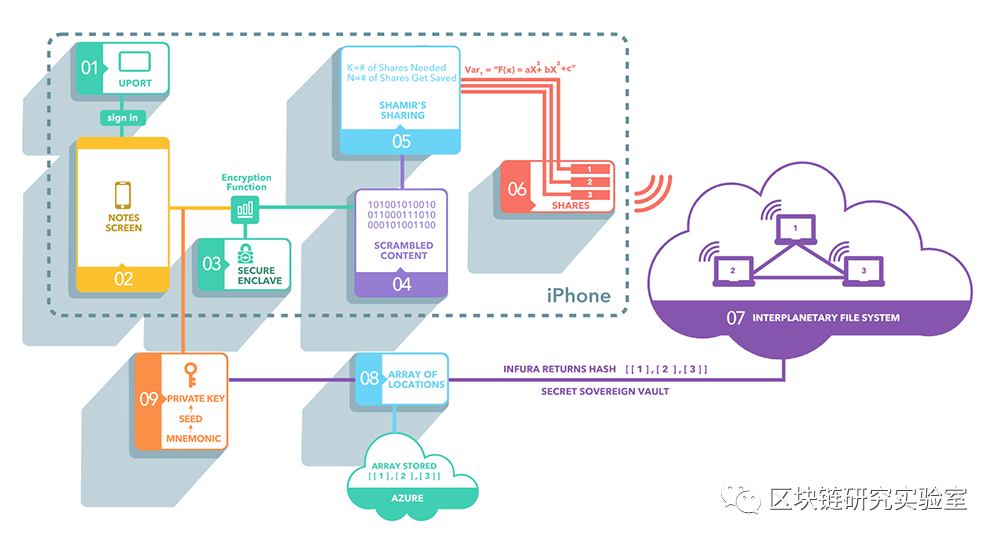
IPFS(行星际文件系统)是用于基于区块链的内容的去中心化存储解决方案。IPFS使用P2P(对等)网络模型进行文件共享,该模型分散并分布在许多计算机或节点上。文件被分解为不同的部分,并存储在节点网络中,这些节点通过哈希跟踪文件。当要查找某个文件时,将根据其哈希值重新创建原始文件。

去中心化文件存储
使用分布式哈希表(DHT)存储和检索文件系统是IPFS的核心创新。它类似于BitTorrent协议,但是它们指向共享文件的方式不同。IPFS是将文件作为键值对存储在区块链上。数据分为256 KB的块,并散布在节点或计算机的网络中。它被有效地协调以实现节点之间的有效访问和查找。BitTorrent不使用区块链,而是依赖Torrent来指向文件。可以有不同的Torrent指向同一个文件,但在IPFS中,你只需要一个指向文件的哈希ID。
文件发布到IPFS的方式与将文件发布到云中的方式不同。IPFS上的所有数据均通过其哈希ID进行寻址。当某人请求该数据时,他们是直接通过其哈希ID而不是实际文件本身来请求该数据。因此IPFS为文件的实际位置提供了一个抽象,因此实际的物理位置对应用程序无关紧要。这种抽象为应用程序开发人员消除了复杂性。

节点在网络上承载文件。IPFS区块链上的Filecoin等数字资产激励他们这么做。激励节点在其计算机或服务器上提供用于托管文件的存储空间。些文件被赋予一个哈希ID,然后可以通过网络分发。其他节点也可以托管同一文件,从而允许制作多个副本。想要该文件的用户将根据离他们位置最近的节点的哈希值来访问它。
托管文件的所有节点都将引用根哈希,该根哈希是文件的哈希ID。每当发出文件请求时,用户就会使用基于其根哈希值存储该文件的最近节点的哈希值来下载文件。IPFS上没有重复项,因为哈希在上载时将始终引用该文件或文件的一部分。
文件放入IPFS区块链后,它将保持可用,直到通过取消文件绑定并运行垃圾收集例程将其删除。文件本身可以具有通过其哈希指向的不同节点。只要存在指向该文件的哈希,不同的节点也可以托管该文件。IPFS可以更新为指向不同的哈希值,但是只要原始节点的哈希值现在或将来的任何时候都可以访问该数据,则至少有一个节点仍在托管该数据。
存储寻址方案
IPFS与典型的基于云的基于Internet的存储系统的区别在于它是基于内容的(内容寻址)而不是基于位置的(位置寻址)。位置寻址存储系统的一个示例是HTTP协议。当存储系统基于位置时,它是指使用DNS服务器通过其主机名来标识服务器。这通过映射到用户友好名称的逻辑寻址方案(例如IP地址)跟踪主机。如果主机更改其名称或地址,则还必须在名称服务表中对其进行修改。
基于内容的寻址存储属于从网络获取数据的内容。这需要确定文件物理位置的内容标识符。在这种情况下,数据是根据其加密哈希而不是逻辑地址来访问的,就像文件的数字指纹一样。网络将始终基于该哈希返回相同的内容,而不管文件的上传者,上传时间和上传时间。
在速度和可靠性方面,IPFS可以比HTTP表现得更好。内容寻址存储系统可以从离用户最近的各种服务器(例如IPFS网络上的对等或节点)提供文件,而不是依赖服务器位置来获取文件。换句话说,用户只需搜索一个文件,而无需搜索引擎引用位置,即服务器名称或地址。相反他们将通过文件的哈希值引用它,并且可以从网络上最近的可用节点中获取该文件。
安装IPFS
有两个节点选项可用于IPF的公共安装。
1. PFS Desktop — 直接在计算机(笔记本电脑或台式机)托管和共享文件。可以安装IPFS配套应用程序,以允许使用Web浏览器访问本地节点。
2. IPFS Cluster — 为了大规模托管和共享文件,该群集支持跨IPFS节点群协调和协调Pinets。这允许通过分布式节点构建大规模的大型文件存储系统。
安装IPFS Desktop后,配置节点首先要初始化存储库。以下是您从Windows Powershell或Mac/Linux终端外壳键入的命令。
ipfsinit>initializingipfsnodeat/Users/<username>/.go-ipfs>generating2048-bitRSAkeypair…done>peeridentity:Qmcpo2iLBikrdf1d6QU6vXuNb6P7hwrbNPW9kLAH8eG67z>togetstarted,enter:>>ipfscat/ipfs/QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG/readme
首次使用IPFS时执行此初始化。下一步是运行IPFS守护进程,以将节点加入网络。
ipfsdaemon>Initializingdaemon…>APIserverlisteningon/ip4/127.0.0.1/tcp/5001>Gatewayserverlisteningon/ip4/127.0.0.1/tcp/8080
这将在本地计算机127.0.0.1上初始化并运行守护进程。它会启动一个侦听TCP端口5001的API服务器和一个侦听TCP端口8080的网关服务器。现在您应该能够通过发出swarm命令看到网络上的其他IPFS节点。它应该如下所示:
ipfsswarmpeers>/ip4/104.131.131.82/tcp/4001/p2p/QmaCpDMGvV2BGHeYERUEnRQAwe3N8SzbUtfsmvsqQLuvuJ>/ip4/104.236.151.122/tcp/4001/p2p/QmSoLju6m7xTh3DuokvT3886QRYqxAzb1kShaanJgW36yx>/ip4/134.121.64.93/tcp/1035/p2p/QmWHyrPWQnsz1wxHR219ooJDYTvxJPyZuDUPSDpdsAovN5>/ip4/178.62.8.190/tcp/4002/p2p/QmdXzZ25cyzSF99csCQmmPZ1NTbWTe8qtKFaZKpZQPdTFB
如IPFS文档中所述,pees采用以下格式:
<transport address>/p2p/<hash-of-public-key>
这是在网络上获取文件的示例命令:
ipfscat/ipfs/QmW2WQi7j6c7UgJTarActp7tDNikE4B2qXtFCfLPdsgaTQ/cat.jpg>cat.jpgopencat.jpg
这将从指定的对等方获取一个名为\’cat.jpg“然后在本地打开。
IPFS的Javascript
以下是使用Runkit NPM和Infura网关(对公众免费)将数据写入IPFS网络的测试代码。
constIPFS=require(\’ipfs-mini\’1.1.5);constipfs=newIPFS({host:\’ipfs.infura.io\’,port:5001,protocol:\’https\’});constdata=\”Writingatestmessageonthenetwork\”;ipfs.add(data,(err,hash)=>{if(err){returnconsole.log(err);}console.log(\’https://ipfs.infura.io/ipfs/\’+hash);})
在这段代码中,我使用require函数在Node.JS上请求“ ipfs-mini”包。然后我配置对Infura IPFS网关“ ipfs.infura.io”的访问。然后我将数据指定为字符串“Writing a test message on the network”。我创建一个条件以在出现问题时返回错误,否则我想要哈希值,然后控制台记录网关的URL和哈希值。
结果将返回唯一的哈希:QmQhadgstSRUv7aYnN25kwRBWtxP1gB9Kowdeim32uf8Td
我现在可以输入URL链接:https://ipfs.infura.io/ipfs/QmQhadgstSRUv7aYnN25kwRBWtxP1gB9Kowdeim32uf8Td
这将显示我刚刚放入Infura网关的数据。数据不是持久性的,几天或几周不活动后将被删除。对于永久数据存储,需要在内部或在云上使用专用服务器。

IPFS的优点
1. 分散化-文件存储在节点网络中,由哈希引用。通过Filecoin激励节点托管文件。
2. 容错-如果一个节点发生故障,只要有托管该文件的节点,该文件仍然可用。没有单点故障。
3. 可扩展性—托管文件的节点越多,网络上的用户就可以变得越快和可用。
4. 持久存储-IPFS的重点是数据存储:只要可以访问与原始数据相对应的对象以及任何新版本,就可以检索整个文件历史记录。假设数据块存储在整个网络的本地并且可以无限期地缓存,这意味着IPFS对象可以永久存储而无需修改。
5. 抵制审查—内容上载到IPFS后,任何中央机构都无法删除它,因为它分布在整个网络中。仅从一个节点删除它不会完全删除该文件。这意味着在其他节点上仍有可用的副本。
IPFS的缺点
对用户不友好
在IPFS网络上建立文件索引的方式不是非常用户友好。例如要通过其哈希ID访问文件,需要输入:ipfs.io/ipns/QmeQe5FTgMs8PNspzTQ3LRz1iMhdq9K34TQnsCP2jqt8wV
开发人员可以使用链接共享文件,但是这可能变得乏味且耗时。IPFS使用IPNS(星际名称系统)来查找文件。IPNS将尝试使名称解析更加用户友好,就像Internet上的DNS一样。
有一个GUI和基于web的扩展IPFS配套应用程序,用户可以使用它来更方便地访问。然而由于学习曲线更加陡峭,它仍然不像普通的智能手机应用程序那样用户友好或简单易用。它不像点击网页上的按钮那么简单。用户必须知道IPFS是如何工作的才能使用它。
数据隐私和合规性
在使用IPFS的公共共享存储系统上放置客户数据(如KYC等个人识别信息(PII))不是最好的用例。首先它违反了存储合规性规则,该规则规定KYC数据不能也不应在公共云或共享存储空间上公开,并且应包括IPFS。在公共云上,对组织管理数据的控制更少。金融机构的严格要求是将数据和数据备份存储在受监管的而非公共存储系统上。这里的另一个问题是,由于它位于公共网络上,因此任何节点都可以托管KYC数据。这进一步违反了严格规定谁可以在何处存储数据的法律。
第二个问题是,所有节点必须符合金融系统的规则和规定,这意味着它们必须具有备份,强大的安全性,容错性等。在公共网络上,这些节点是随机的,不能让它们遵守规则,因为它们不必信任您的系统。他们还可以将KYC数据提供给网络上的其他用户,即使行为被加密,恶意参与者也可以访问。他们可以自己解密,这为他们提供了一条途径。
数据不一致
在IPFS上,节点维护网络上数据的长期备份的动机也很小。节点可以选择清除缓存的数据以节省空间,这意味着从理论上讲,如果没有剩余的节点托管数据,文件最终会随着时间的流逝而“消失”。在当前的采用水平上,这不是一个大问题,但从长远来看,备份大量数据需要强大的经济动力。
这里的问题是,如果公司使用公共IPFS网络进行文件存储,则节点可以随时选择不将来托管文件。如果所有节点都决定执行此操作,则除非IPFS托管在专用网络上,否则无法将文件保留在网络上。根据IPFS协议,如果您添加到IPFS网络的文件没有被很多人访问,它将消失。您的数据需要在网络上更加流行才能使其永久存在。如果您不希望数据从IPFS网络中消失,则必须将数据固定在节点上。固定可确保通过网络至少您的节点拥有该数据。
由于IPFS是分散式的,因此所有托管节点都将拥有您上载的文件的副本。通常如果文件不活跃或不经常使用,则将其删除。这可能是一个非常有争议的问题,因为有时文件已被归档并且不经常使用,有时还需要立即删除。当已经存储在IPFS上的数据发生更改时,其哈希也必须更改。如果有新版本,则必须上载,但不会覆盖旧版本。这会影响到文件的现有链接,因此原始文件保持不变,但是现在您需要为新文件创建一个新链接。
更新KYC数据时,这可能是一个挑战。这些文档过期后,必须上载新版本以替换旧版本。IPFS提供了版本控制,但是一旦将其放在公共网络上就会变得棘手,因为可以从不同的节点存在许多版本。旧版本不会自动更新。旧的必须存档或销毁。IPFS不能以与AWS或Azure相同的方式存档文件。
IPFS确实有一个版本控制系统。这是IPFS的Merkle-DAG结构的一个特性,它允许您构建分布式版本控制系统(VCS)。最受欢迎的示例是Github,它使开发人员可以轻松地同时在项目上进行协作。Github上的文件使用Merkle DAG进行存储和版本控制。它允许用户独立地复制和编辑一个文件的多个版本,存储这些版本,以及以后与原始文件合并编辑。但是根据许多开发人员的观点,从理论上讲,这几乎是可行的,但还没有一种经过充分测试和验证的有效的技术(在撰写本文时)。如果我们要实施它,那将需要更多的时间和开发成本,从长远来看可能是好的。
———————————–
原文作者:Vince Tabora
原文链接:https://medium.com/0xcode/using-ipfs-for-distributed-file-storage-systems-61226e07a6f
译者:链三丰
———————————–
相关文章阅读:
区块链研究实验室|如何使用IPFS和以太坊ENS自动发布去中心化网站
区块链研究实验室|使用Node.Js构建IPFS应用程序
区块链研究实验室| 文件存储在IPFS上是否足够安全和隐秘?
本文来源:陀螺财经原文标题:区块链研究实验室|在分布式文件存储系统中使用IPFS